Berbicara tentang algoritma big data, kita sering membicarakan apa yang disebut penambangan data, proses mengotomatisasi proses penyortiran kumpulan big data, mengidentifikasi tren dan pola dan membangun korelasi.
Perusahaan data di pasar saat ini mengumpulkan sejumlah besar informasi melalui berbagai saluran, dari situs web, aplikasi perusahaan, media sosial, perangkat seluler, dan Internet of Things yang terus berkembang.
Misalnya mesin pencari yang kita gunakan setiap hari. Di bidang pemrosesan bahasa alami, ada model algoritma yang sangat populer yang disebut model bag-of-words, yang memperlakukan sepotong teks sebagai sekantong buah-buahan.
Model ini untuk menghitung berapa banyak apel, berapa banyak pisang, dan berapa banyak banyak buah pir dalam kantong buah. Mesin pencari akan mencatat angka-angka ini, dan jika Anda menginginkan apel, Maka itu akan memberi Anda tas-tas ini dengan apel.
Saat kami membeli sesuatu secara online atau menonton film, situs web akan merekomendasikan beberapa produk atau film yang mungkin cocok dengan preferensi kami dan rekomendasi ini terkadang akurat.
Sebenarnya, algoritme di balik ini adalah untuk menghitung berapa banyak film yang Anda sukai yang sama dengan film orang lain. Jika Anda menyukai lebih dari beberapa film pada saat yang sama, Anda akan menyukai orang lain tetapi Anda belum menontonnya Film yang direkomendasikan untuk Anda.
Mesin pencari dan sistem pemberi rekomendasi memiliki banyak pekerjaan ekstra yang harus dilakukan di lingkungan produksi nyata, tetapi pada dasarnya mereka menghitung.
Ketika jumlah data relatif kecil, data dapat diperiksa secara manual. Di era big data, ratusan terabyte atau bahkan petabyte data hanyalah beberapa kesimpulan numerik dalam laporan para analis atau bos.
Dalam proses penghitungan, informasi yang ada dalam data juga dibuang, dan nilai informasi yang diwakili oleh angka-angka yang tersisa tidak sama dengan nilai sebenarnya.
Selama beberapa dekade terakhir, banyak perusahaan telah menghabiskan banyak uang menggunakan Internet of Things dan komputasi awan untuk mengumpulkan data dalam jumlah besar. Hanya untuk menemukan bahwa manfaatnya tidak sebanyak yang mereka kira.
Jadi kita sekarang berada di era “digital everything “. Semua perilaku orang akan diubah menjadi data dan disimpan dengan beberapa cara digital.
Setiap Tahun Baru, situs web dan aplikasi utama akan mengirimkan laporan ulasan tahun sebelumnya kepada pengguna. Misalnya, Paypal akan memberi tahu pengguna berapa banyak yang mereka belanjakan pada tahun lalu, berapa banyak yang mereka beli di E-commerce, dan ke mana mereka pergi makan.
Aplikasi travel merekam Perjalanan Udara dan akan memberi tahu pengguna berapa banyak pesawat yang dia ambil tahun lalu total jarak tempuh penerbangan, dan kota-kota yang paling banyak dikunjungi.
Akhirnya memberi tahu pengguna rencana perjalanannya Berapa banyak teman yang berakhir. Laporan ini terlihat sangat keren, dan mereka disebut “big data“, yang membuat pengguna berpikir betapa hebatnya teknologi ini.
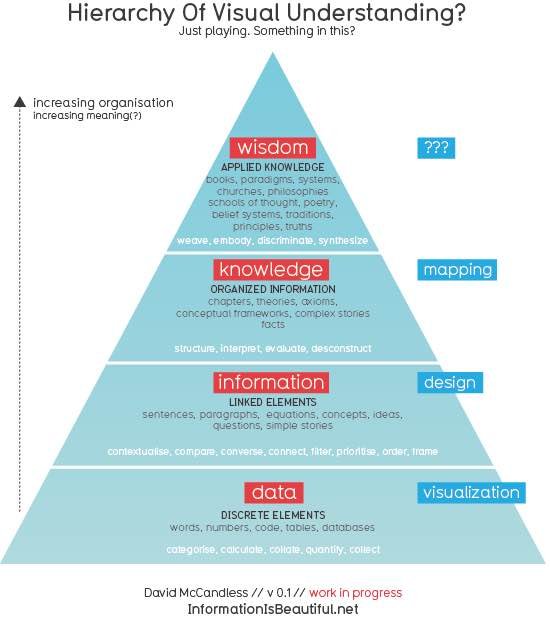
Padahal, penggunaan dan analisis data oleh perusahaan tidak lebih rumit dari laporan tahunan yang kami terima setiap tahun.
Intelijen bisnis yang memiliki sejarah lebih dari 30 tahun, terlihat sangat keren. Tetapi esensinya masih menghitung dan menggambar hasil penghitungan untuk dilihat manajer.
Hanya saja dalam industri dan skenario yang berbeda, angka dan grafik yang sama akan memiliki nama yang berbeda. Bahkan teknologi pemrosesan big data yang populer dalam beberapa tahun terakhir hanya dapat menghitung lebih banyak dan lebih cepat.
Algoritma Apa Yang Digunakan Dalam Pemrosesan Big Data?
1. Search Algorithms A*
Graph search algorithms yang menghitung jalur dari titik awal tertentu ke titik akhir tertentu. Estimasi heuristik digunakan untuk memperkirakan jalur terbaik melalui node untuk setiap node dan menggunakannya untuk menentukan peringkat lokasi. Algoritme mengunjungi node ini dalam urutan yang dihasilkan. Oleh karena itu, algoritma pencarian A* adalah contoh pencarian pertama yang lebih baik.
2. Beam Search
Juga dikenal sebagai directional search, Beam Search. Optimasi algoritma pencarian prioritas terbaik. Gunakan fungsi heuristik untuk mengevaluasi kemampuan setiap node yang diperiksanya.
Namun, pencarian balok hanya dapat menemukan m teratas node yang paling memenuhi syarat di setiap kedalaman, di mana m adalah angka tetap lebar balok.
3. Binary Search
Algoritma untuk menemukan nilai tertentu dalam array linier, menghapus setengah dari data yang tidak memenuhi persyaratan pada setiap langkah.
4. Branch and Bound
Algoritma untuk menemukan solusi optimal spesifik dalam berbagai masalah optimasi, terutama untuk optimasi diskrit dan kombinatorial.
5. Algoritma Buchberger Big Data
Algoritma matematika yang dapat dianggap sebagai generalisasi dari algoritma Euclidean untuk memecahkan pembagi persekutuan yang lebih besar dari variabel tunggal dan eliminasi Gaussian dalam sistem linier.
6. Data Compression
Proses menggunakan skema pengkodean khusus untuk mengkodekan informasi dengan lebih sedikit byte (atau unit pembawa informasi lainnya), juga dikenal sebagai pengkodean sumber.
7. Algoritma Diffie-Hellman Big Data
Protokol enkripsi yang memungkinkan dua pihak untuk bersama-sama membuat kunci bersama dalam saluran komunikasi yang tidak aman tanpa saling mengenal sebelumnya. Kunci ini nantinya dapat digabungkan dengan sandi simetris untuk mengenkripsi komunikasi berikutnya.
8. Algoritma Dijkstra
Untuk graf berarah tanpa sisi bobot negatif, hitung algoritma terpendek untuk satu titik awal.
9. Discrete differentiation
Baca juga : Kampus Jurusan Data Science Populer Dunia Yang Lulusanya Paling Banyak Dicari
10. Dynamic Programming
Mendemonstrasikan sub-masalah dan algoritma sub-arsitektur optimal yang saling menutupi
11. Algoritma Euclidean Big Data
Menghitung pembagi persekutuan yang lebih besar dari dua bilangan bulat. Salah satu algoritma tertua, yang muncul di Elemen Euclid sebelum 300 SM.
12. Expectation Maximization Algorithm
Juga dikenal sebagai EM-Training Dalam komputasi statistik, algoritma Ekspektasi-Maximization mencari perkiraan parameter yang lebih mungkin dalam model probabilistic. Di mana model bergantung pada variabel laten yang ditemukan. EM dihitung secara bergantian dalam dua langkah.
Langkah pertama adalah menghitung ekspektasi, menggunakan estimasi variabel tersembunyi yang ada untuk menghitung kemungkinan estimasinya yang lebih besar.
Langkah kedua adalah memaksimalkan, dan maksimum pada langkah pertama. Temukan kemungkinan nilai yang lebih besar untuk menghitung nilai parameter.
13. Fast Fourier Transform (FFT)
Menghitung transformasi Fourier diskrit (DFT) dan kebalikannya. Algoritme memiliki cakupan aplikasi yang luas, mulai dari pemrosesan sinyal digital hingga penyelesaian persamaan diferensial parsial, hingga komputasi produk bilangan bulat besar dengan cepat.
14. Gradient Descent
Algoritma optimasi matematis.
15. Algoritma Hashing Big Data
Baca juga : Perkembangan Big Data Dampak Resiko Dan Prospek Pekerjaan
16. Heaps
Baca juga : Perbedaan Antara Data Informasi Digitalisasi Dan Kecerdasan
17. Karatsuba
Digunakan dalam sistem yang perlu menyelesaikan perkalian ribuan bilangan bulat. Seperti sistem aljabar komputer dan perpustakaan bilangan besar. Jika perkalian panjang digunakan, kecepatannya terlalu lambat. Algoritma ini ditemukan pada tahun 1962.
18. Algoritma LLL (Lenstra-Lenstra-Lovasz lattice reduction)
Mengambil spesifikasi kisi (lattice) kardinalitas sebagai input dan output kardinalitas vektor ortogonal pendek. Algoritme LLL banyak digunakan dalam metode enkripsi kunci publik berikut: knapsack, enkripsi RSA dengan pengaturan tertentu, dll.
19. Algoritma Maximum flow Big Data
Algoritma ini mencoba untuk menemukan aliran yang lebih besar dari jaringan aliran. Keuntungannya didefinisikan sebagai menemukan nilai aliran seperti itu. Masalah aliran yang lebih besar dapat dilihat sebagai kasus spesifik dari masalah aliran jaringan yang lebih kompleks.
Aliran yang lebih besar terkait dengan antarmuka dalam jaringan, yang merupakan teorema min-cut Max-flow. Ford-Fulkerson dapat menemukan aliran yang lebih besar dalam jaringan aliran.
20. Merge Sort
21. Metode Newton
Metode iteratif yang penting untuk menemukan nol dari persamaan (grup) nonlinier.
22. Algoritme Pembelajaran Q-learning Big Data
ini adalah algoritme pembelajaran penguatan yang diselesaikan dengan mempelajari fungsi nilai tindakan.
Fungsi tersebut mengambil tindakan yang diberikan dalam keadaan tertentu dan menghitung nilai utilitas yang diharapkan.
Strategi tetap diikuti setelahnya. Keuntungan dari Q-learing adalah bahwa utilitas yang diharapkan dari tindakan yang dapat ditindaklanjuti dapat dibandingkan tanpa memerlukan model lingkungan.
23. Quadratic Sieve
Algoritme faktorisasi bilangan bulat modern, dalam praktiknya, adalah algoritme tercepat kedua dari jenisnya yang diketahui (setelah Saringan Bidang Angka).
Ini masih yang tercepat untuk bilangan bulat sepuluh digit di bawah 110, dan dianggap lebih sederhana daripada metode saringan bidang angka.
24. RANSAC
Adalah singkatan dari “RANdom SAmple Consensus”. Algoritme memperkirakan nilai parameter model matematika berdasarkan serangkaian data yang diamati, termasuk outlier.
Asumsi dasarnya adalah bahwa data berisi nilai-nilai yang tidak diasingkan, yaitu nilai-nilai yang dapat dijelaskan oleh parameter model tertentu, dan bahwa nilai-nilai yang diasingkan adalah titik-titik data yang tidak sesuai dengan model.
25. RSA
Algoritma enkripsi kunci publik. Yang sebelumnya berlaku untuk algoritma yang menggunakan tanda tangan sebagai enkripsi. RSA masih digunakan dalam skala besar di industri e-commerce, dan semua orang percaya bahwa ia memiliki kunci publik dengan panjang keamanan yang cukup
26. Algoritma Schönhage-Strassen
Dalam matematika, algoritma Schönhage-Strassen adalah algoritma asimtotik cepat yang digunakan untuk melakukan perkalian bilangan bulat besar. Kompleksitas algoritma adalah: O(N log(N) log(log(N))), yang menggunakan transformasi Fourier.
27. Algoritma Simpleks Big Data
Dalam teori optimasi matematika, algoritma simpleks adalah teknik yang umum digunakan untuk menemukan solusi numerik untuk masalah pemrograman linier. Masalah pemrograman linier terdiri dari serangkaian pertidaksamaan linier atas satu set variabel nyata, dan fungsi linier tetap menunggu untuk dimaksimalkan (atau diminimalkan).
28. Singular Value Decomposition (SVD) Algoritma Big Data
Dalam aljabar linier, SVD adalah metode dekomposisi penting dari matriks real atau kompleks. Ini memiliki banyak aplikasi dalam pemrosesan sinyal dan statistic.
Seperti menghitung kebalikan semu dari sebuah matriks. memecahkan masalah kuadrat terkecil), memecahkan sistem linier yang ditentukan lebih, pendekatan matriks, prakiraan cuaca numerik, dll.
29. Solving A System Of Linear Equations
Persamaan linier adalah masalah tertua dalam matematika, dan memiliki banyak aplikasi, seperti dalam pemrosesan sinyal digital, estimasi dan prediksi dalam pemrograman linier, dan dalam analisis numerik.
Aproksimasi masalah nonlinier, dll. Untuk menyelesaikan sistem persamaan linear, eliminasi Gauss-Jordan atau dekomposisi Cholesky dapat digunakan.
30. Algoritma Strukturtensor Big Data
Diterapkan pada bidang pengenalan pola, menemukan metode perhitungan untuk semua piksel, melihat apakah piksel berada di wilayah yang homogen, dan melihat apakah itu milik tepi atau simpul.
31. Union-find
Mengingat satu set elemen, algoritma ini sering digunakan untuk membagi elemen-elemen ini menjadi beberapa grup yang terpisah dan tidak tumpang tindih. Struktur data yang terpisah dapat melacak metode pemisahan tersebut. Algoritma pencarian gabungan dapat melakukan dua operasi yang berguna pada struktur data tersebut:
Temukan: Tentukan kelompok mana yang dimiliki elemen tertentu.
Merge: Menggabungkan dua grup menjadi satu grup.
32. Algoritma Viterbi Big Data
Algoritma pemrograman dinamis untuk menemukan urutan paling mungkin dari keadaan tersembunyi, yang dikenal sebagai jalur Viterbi. Hasilnya adalah urutan peristiwa yang dapat diamati, terutama di Markov tersembunyi dalam model.





