Di bawah ini adalah pertanyaan tentang wawancara seputar big data terpopuler, ditambah dengan jawaban terperinci untuk pertanyaan spesifik. Untuk pertanyaan yang lebih luas, jawabannya bergantung pada pengalaman Anda dan Labkom99 akan membagikan beberapa kiat tentang cara menjawabnya.
Era big data sudah dimulai dan semakin banyak perusahaan beralih ke big data untuk menjalankan bisnis mereka. Permintaan akan talenta pada teknologi big data menjadi tinggi. Apa artinya ini bagi Anda?
Ini berarti peluang yang lebih baik jika Anda ingin bekerja dalam peran karir big data. Anda dapat memilih untuk menjadi analis data, data science, administrator basis data, insinyur big data, insinyur big data Hadoop dan sebagainya.
50 Pertanyaan Wawancara Tentang Big Data Paling Populer
Untuk memberikan keunggulan pada karir Anda, Anda harus siap untuk wawancara big data. Sebelum Anda mulai, penting untuk memahami bahwa wawancara adalah tempat di mana Anda dan pewawancara berinteraksi, saling mengenal, bukan satu sama lain.
Jadi Anda tidak perlu menyembunyikan apa pun, cukup jujur dan jawab pertanyaan dengan jujur. Jika Anda bingung atau membutuhkan informasi lebih lanjut, jangan ragu untuk bertanya kepada pewawancara. Selalu jujur dengan jawaban Anda dan ajukan pertanyaan bila diperlukan.
Pertanyaan Wawancara Dasar Tentang Big Data
Setiap kali Anda melakukan wawancara big data, pewawancara akan menanyakan beberapa pertanyaan dasar. Apakah Anda baru di bidang big data atau orang yang berpengalaman, pengetahuan dasar diperlukan. Jadi, mari kita bahas beberapa pertanyaan dan jawaban wawancara big data dasar yang umum untuk memecahkan wawancara big data.
1. Apa Yang Anda Ketahui Tentang Istilah “Big Data“?
Jawaban :
Big data adalah istilah yang terkait dengan kumpulan data yang kompleks dan besar. Basis data relasional tidak dapat menangani big data, itulah sebabnya alat dan metode khusus digunakan untuk melakukan operasi pada data dalam jumlah besar.
Big data memungkinkan perusahaan untuk lebih memahami bisnis mereka dan membantu mereka memperoleh informasi yang berarti dari data mentah dan tidak terstruktur yang dikumpulkan secara teratur. Big data juga memungkinkan perusahaan untuk membuat keputusan bisnis yang lebih baik berdasarkan data.
2. Apa Lima Vs Dari Big Data? Pertanyaan Dasar Tentang Big Data
Jawaban :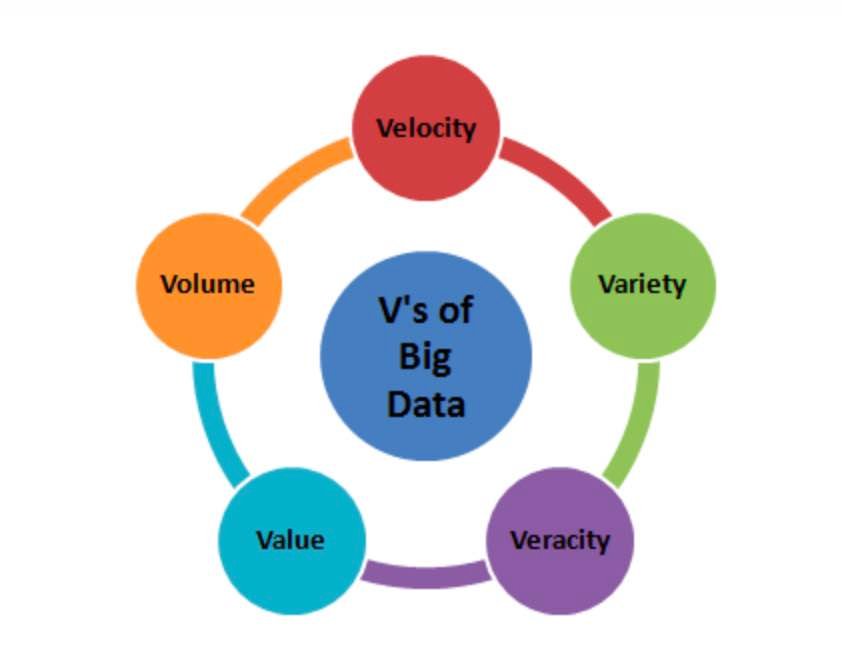
Lima Vs dari big data adalah sebagai berikut:
- Volume – Volume berarti volume, yaitu jumlah data yang tumbuh dengan kecepatan tinggi, yaitu jumlah data dalam petabyte
- Velocity – Velocity adalah kecepatan pertumbuhan data. Media sosial memainkan peran utama dalam laju pertumbuhan data.
- Variety – Variety mengacu pada tipe data yang berbeda, yaitu berbagai format data seperti teks, audio, video, dll.
- Veracity – Akurasi mengacu pada ketidakpastian data yang tersedia. Akurasi terjadi karena ketidaklengkapan dan ketidakkonsistenan yang disebabkan oleh sejumlah besar data.
- Value– Value mengacu pada mengubah data menjadi nilai. Dengan mengubah big data yang diakses menjadi nilai, bisnis dapat menghasilkan pendapatan.
Catatan: Ini adalah salah satu pertanyaan mendasar dan penting yang diajukan dalam wawancara big data. Jika Anda melihat pewawancara tertarik untuk mempelajari lebih lanjut, Anda dapat memilih untuk menjelaskan kelima V secara rinci. Namun, jika ada yang bertanya tentang istilah “big data”, nama-nama ini pun bisa disebutkan.
3. Ceritakan Tentang Hubungan Antara Big Data Dan Hadoop.
Jawaban :
Big data dan Hadoop hampir identik. Dengan munculnya big data, kerangka Hadoop yang didedikasikan untuk operasi big data juga menjadi populer. Profesional dapat menggunakan kerangka kerja untuk menganalisis big data dan membantu bisnis membuat keputusan.
Catatan: Pertanyaan ini sering ditanyakan saat wawancara big data. Anda dapat melangkah lebih jauh untuk menjawab pertanyaan ini dan mencoba menjelaskan komponen utama Hadoop.
4. Bagaimana Analitik Big Data Dapat Membantu Meningkatkan Pendapatan Bisnis?
Jawaban :
Analisis big data menjadi sangat penting bagi bisnis. Ini dapat membantu bisnis membedakan diri mereka sendiri dan meningkatkan pendapatan. Melalui analitik prediktif, analitik big data memberi bisnis rekomendasi yang disesuaikan.
Selain itu, analitik big data memungkinkan bisnis meluncurkan produk baru berdasarkan kebutuhan dan preferensi pelanggan. Faktor-faktor ini memungkinkan bisnis memperoleh lebih banyak pendapatan. Sehingga perusahaan menggunakan analitik big data.
Dengan menerapkan analitik big data, pendapatan perusahaan dapat meningkat secara substansial sebesar 5-20%. Beberapa perusahaan populer yang menggunakan analitik big data untuk meningkatkan pendapatan adalah – Walmart, LinkedIn, Facebook, Twitter, Bank of America, dll.
5. Jelaskan Langkah-Langkah Yang Harus Diikuti Untuk Menerapkan Solusi Big Data.
Jawaban :
Berikut adalah tiga langkah untuk menerapkan solusi big data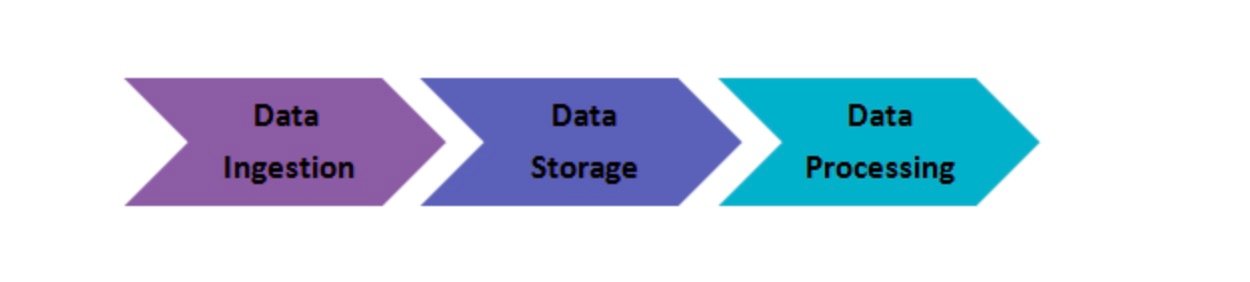
(1) Pengambilan data
Langkah pertama dalam menerapkan solusi big data adalah penyerapan data, yang merupakan ekstraksi data dari berbagai sumber. Sumber data dapat berupa CRM seperti Salesforce, sistem perencanaan sumber daya perusahaan seperti SAP, RDBMS seperti MySQL atau file log lainnya, dokumen, sumber media sosial, dll. Data dapat diserap melalui pekerjaan batch atau streaming waktu nyata. Data yang diekstraksi kemudian disimpan dalam HDFS.
(2) Penyimpanan data
Setelah mengekstrak data, langkah selanjutnya adalah menyimpan data yang diekstraksi. Data dapat disimpan dalam database HDFS atau NoSQL (yaitu HBase). Penyimpanan HDFS cocok untuk akses sekuensial, sedangkan HBase cocok untuk akses baca/tulis acak.
(3) Pemrosesan data
Langkah terakhir dalam menerapkan solusi big data adalah pemrosesan data. Data diproses melalui salah satu kerangka pemrosesan seperti Spark, MapReduce, Pig, dll.
6. Tentukan Berbagai komponen HDFS dan YARN? Pertanyaan Tentang Big Data
Jawaban :
Dua komponen utama HDFS adalah
- NameNode – Ini adalah master node yang menangani informasi metadata untuk blok data di HDFS
- DataNode/Slave node – ini adalah node yang bertindak sebagai slave node untuk menyimpan data untuk NameNode untuk diproses dan digunakan
Selain memenuhi permintaan klien, NameNode melakukan salah satu dari dua peran:
- CheckpointNode – ini berjalan pada host yang berbeda dari NameNode
- BackupNode – Ini adalah NameNode read-only yang berisi informasi metadata filesystem (tidak termasuk posisi blok)
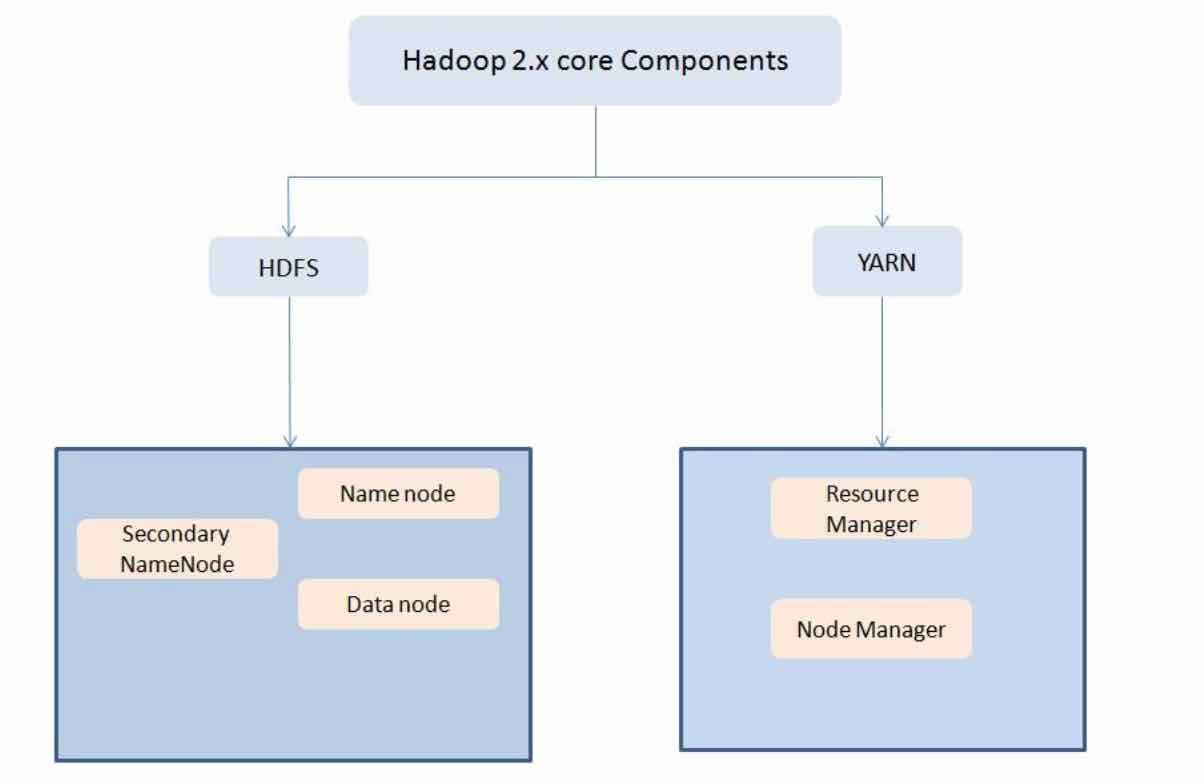
Dua komponen utama YARN adalah
- ResourceManager – Komponen ini menerima permintaan pemrosesan dan menetapkan sesuai dengan NodeManager yang sesuai berdasarkan kebutuhan pemrosesan.
- NodeManager – menjalankan tugas pada setiap node data
7. Mengapa Menggunakan Hadoop Untuk Analitik Big Data?
Jawaban :
Karena analitik data telah menjadi salah satu parameter utama bisnis, bisnis berurusan dengan volume besar data terstruktur, tidak terstruktur dan semi-terstruktur. Menganalisis data tidak terstruktur sangat sulit dengan Hadoop sebagai peran utamanya. Baca juga Perbedaan Antara Database Relasional Dan Non-Relasional.
- Penyimpanan
- Pengolahan
- pengumpulan data
Juga, Hadoop adalah open source dan berjalan pada perangkat keras komoditas. Oleh karena itu, ini adalah solusi hemat biaya untuk bisnis.
8. Apa Itu Fsck?
Jawaban :
fsck adalah singkatan dari file system check. Ini adalah perintah yang digunakan oleh HDFS. Perintah ini digunakan untuk memeriksa inkonsistensi dan jika ada masalah dalam file. Misalnya, jika file tidak memiliki blok apa pun, HDFS akan diberi tahu dengan perintah ini.
9. Apa Perbedaan Utama Antara NAS (Network Attached Storage) Dan HDFS?
Jawaban :
Perbedaan utama antara NAS (Network Attached Storage) dan HDFS
- HDFS berjalan pada sekelompok komputer, sementara NAS berjalan pada satu komputer. Oleh karena itu, redundansi data adalah masalah umum di HDFS. Sebaliknya, dengan NAS, protokol replikasinya berbeda. Oleh karena itu, kemungkinan redundansi data jauh lebih kecil.
- Untuk HDFS, data akan disimpan di drive lokal sebagai blok data. Untuk NAS, disimpan dalam perangkat keras khusus.
10. Apa Perintah Untuk Memformat Namenode?
Jawaban :
$ hdfs namenode -format
Pertanyaan Wawancara Tentang Big Data Berbasis Pengalaman
Jika Anda memiliki pengalaman kerja yang cukup besar di dunia big data, Anda akan ditanyai banyak pertanyaan dalam wawancara big data berdasarkan pengalaman Anda sebelumnya. Pertanyaan-pertanyaan ini mungkin hanya terkait dengan pengalaman atau skenario Anda. Jadi bersiaplah dengan pertanyaan dan jawaban wawancara big data terbaik ini
11. Apakah Anda Memiliki Pengalaman Big Data? Jika Demikian, Silakan Berbagi Dengan Kami.
Jawaban :
Cara mengatasinya: Karena pertanyaan ini subjektif, tidak ada jawaban khusus dan jawabannya tergantung pada pengalaman Anda sebelumnya. Saat menanyakan pertanyaan ini dalam wawancara big data, pewawancara ingin tahu tentang pengalaman Anda sebelumnya dan juga mencoba menilai kesesuaian Anda untuk persyaratan proyek.
Jadi bagaimana Anda akan menghadapi ini? Jika Anda memiliki pengalaman sebelumnya, mulailah dengan peran sebelumnya dan perlahan tambahkan detail ke percakapan. Beri tahu mereka tentang kontribusi Anda untuk menyukseskan proyek. Pertanyaan ini biasanya merupakan pertanyaan kedua atau ketiga yang diajukan dalam sebuah wawancara. Pertanyaan selanjutnya didasarkan pada pertanyaan ini, jadi tolong jawab dengan hati-hati. Anda juga harus berhati-hati untuk tidak melakukan pekerjaan sebelumnya secara berlebihan. Tetap sederhana dan jelas.
12. Apakah Anda Lebih Suka Data Yang Baik Atau Model Yang Baik? Mengapa?
Jawaban :
Cara mengatasinya: Ini adalah pertanyaan yang sulit, tetapi biasanya ditanyakan dalam wawancara big data. Ini meminta Anda untuk memilih antara data yang baik atau model yang baik. Sebagai kandidat, Anda harus mencoba menjawab berdasarkan pengalaman Anda sendiri.
Banyak perusahaan ingin mengikuti proses evaluasi data yang ketat, yang berarti mereka telah memilih model data. Dalam hal ini, memiliki data yang baik dapat menjadi pengubah permainan. Cara lain adalah memilih model berdasarkan data yang baik.
Seperti yang disebutkan, tolong jawab berdasarkan pengalaman Anda. Tapi jangan bilang punya data bagus dan model bagus itu penting, karena di kehidupan nyata sulit memiliki keduanya.
13. Apakah Anda Mengoptimalkan Algoritme Atau Kode Agar Berjalan Lebih Cepat?
Jawaban :
Cara mengatasinya: Jawaban atas pertanyaan ini harus selalu “ya”. Kinerja dunia nyata penting, tidak tergantung pada data atau model yang Anda gunakan dalam proyek Anda. Baca Berbagai Algoritma Big Data Yang Biasa Digunakan Untuk Pengolahan Data.
Pewawancara mungkin juga ingin tahu apakah Anda memiliki pengalaman sebelumnya dengan pengoptimalan kode atau algoritme. Sebagai permulaan, itu jelas tergantung pada proyek yang dia kerjakan di masa lalu.
Kandidat yang berpengalaman juga dapat berbagi pengalaman mereka. Namun, jujurlah dengan pekerjaan Anda, tidak apa-apa jika Anda belum mengoptimalkan kode Anda di masa lalu. Anda dapat memecahkan wawancara big data hanya dengan memberi tahu pewawancara tentang pengalaman dunia nyata Anda.
14. Bagaimana Anda Melakukan Persiapan Data? Pertanyaan Tentang Big Data
Jawaban :
Bagaimana melakukannya: Persiapan data adalah salah satu langkah kunci dalam proyek teknologi big data. Wawancara big data mungkin melibatkan setidaknya satu pertanyaan berdasarkan persiapan data. Ketika pewawancara menanyakan pertanyaan ini kepada Anda, dia ingin tahu langkah atau tindakan pencegahan apa yang Anda ambil dalam proses persiapan data.
Seperti yang Anda ketahui, persiapan data diperlukan untuk mendapatkan data yang diperlukan, yang kemudian dapat digunakan lebih lanjut untuk keperluan pemodelan. Anda harus mengomunikasikan informasi ini kepada pewawancara.
Anda juga harus menonjolkan jenis model yang akan digunakan dan alasan memilih model tersebut. Last but not least, Anda juga harus mendiskusikan istilah persiapan data penting seperti mengubah variabel, outlier, data tidak terstruktur, mengidentifikasi kesenjangan, dll.
15. Bagaimana Cara Mengubah Data Tidak Terstruktur Menjadi Data Terstruktur?
Jawaban :
Cara mengatasinya: Data tidak terstruktur sangat umum di big data. Data tidak terstruktur harus dikonversi menjadi data terstruktur untuk memastikan analisis data yang tepat. Anda dapat mulai menjawab pertanyaan dengan membedakan keduanya secara singkat.
Setelah itu selesai, Anda sekarang dapat mendiskusikan cara untuk mengonversi satu bentuk ke bentuk lainnya. Anda juga dapat berbagi situasi yang sebenarnya. Jika Anda baru saja lulus, Anda dapat berbagi informasi terkait program akademik Anda.
Dengan menjawab pertanyaan ini dengan benar, Anda menunjukkan bahwa Anda memahami jenis data terstruktur dan tidak terstruktur dan memiliki pengalaman praktis bekerja dengan data ini. Jika Anda menjawab pertanyaan itu secara spesifik, maka Anda pasti dapat memecahkan wawancara big data.
16. Konfigurasi Perangkat Keras Mana Yang Terbaik Untuk Pekerjaan Hadoop?
Jawaban :
Dual Prosesor atau komputer core dengan RAM 4/8 GB dan memori ECC ideal untuk menjalankan operasi Hadoop. Namun, konfigurasi perangkat keras akan bervariasi berdasarkan alur kerja dan alur pemrosesan khusus proyek, sehingga penyesuaian akan diperlukan.
17. Apa Yang Terjadi Ketika Dua Pengguna Mencoba Mengakses File Yang Sama Dalam HDFS?
Jawaban :
HDFS NameNode hanya mendukung penulisan eksklusif. Oleh karena itu, hanya pengguna pertama yang akan diberikan akses ke file, dan pengguna kedua akan ditolak.
18. Bagaimana Memulihkan Ketika Namenode Gagal? Pertanyaan Tentang Big Data
Jawaban :
Langkah-langkah berikut diperlukan agar klaster Hadoop berfungsi dengan baik:
- Mulai NameNode baru dengan salinan metadata sistem file, FsImage.
- Konfigurasikan datanodes dan klien untuk mengakui namenodes yang baru dimulai.
- Setelah NameNode baru selesai memuat FsImage pos pemeriksaan terakhir yang menerima laporan pemblokiran yang cukup dari DataNode, ia akan mulai melayani klien.
Untuk kluster Hadoop yang besar, proses pemulihan NameNode dapat memakan banyak waktu, menjadikannya tantangan yang lebih besar untuk pemeliharaan rutin.
19. Apa Yang Anda Ketahui Tentang Rak Di Hadoop?
Jawaban :
Ini adalah algoritme yang diterapkan pada NameNode untuk menentukan cara menempatkan blok dan replikanya. Lalu lintas jaringan diminimalkan antara DataNodes dalam rak yang sama sesuai dengan definisi rak. Misalnya, jika kita mengatur faktor replikasi ke 3, dua replika ditempatkan di satu rak dan replika ketiga ditempatkan di rak terpisah.
20. Apa Perbedaan Antara “Blok HDFS” Dan “Pemisahan Input”?
Jawaban :
HDFS secara fisik membagi data input ke dalam blok untuk diproses, yang disebut blok HDFS.
Pemisahan input adalah pembagian logis data oleh mapper untuk operasi pemetaan.





